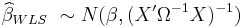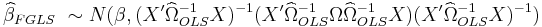Generalized least squares
In statistics, generalized least squares (GLS) is a technique for estimating the unknown parameters in a linear regression model. The GLS is applied when the variances of the observations are unequal (heteroscedasticity), or when there is a certain degree of correlation between the observations. In these cases ordinary least squares can be statistically inefficient, or even give misleading inferences.
Contents |
Method outline
In a typical linear regression model we observe data 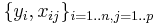 on n statistical units. The response values are placed in a vector Y = (y1, ..., yn)′, and the predictor values are placed in the design matrix X = [[xij]], where xij is the value of the jth predictor variable for the ith unit. The model assumes that the conditional mean of Y given X is a linear function of X, whereas the conditional variance of Y given X is a known matrix Ω. This is usually written as
on n statistical units. The response values are placed in a vector Y = (y1, ..., yn)′, and the predictor values are placed in the design matrix X = [[xij]], where xij is the value of the jth predictor variable for the ith unit. The model assumes that the conditional mean of Y given X is a linear function of X, whereas the conditional variance of Y given X is a known matrix Ω. This is usually written as
![Y = X\beta %2B \varepsilon, \qquad \mathrm{E}[\varepsilon|X]=0,\ \operatorname{Var}[\varepsilon|X]=\Omega.](/2012-wikipedia_en_all_nopic_01_2012/I/4dc7478e26430c59dfb4deb76f4fdf39.png)
Here β is a vector of unknown “regression coefficients” that must be estimated from the data.
Suppose b is a candidate estimate for β. Then the residual vector for b will be Y − Xb. Generalized least squares method estimates β by minimizing the squared Mahalanobis length of this residual vector:
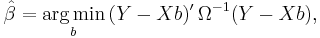
Since the objective is a quadratic form in b, the estimator has an explicit formula:
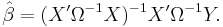
Properties
The GLS estimator is unbiased, consistent, efficient, and asymptotically normal:
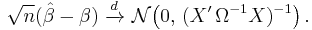
GLS is equivalent to applying ordinary least squares to a linearly transformed version of the data. To see this, factor Ω = BB′, for instance using the Cholesky decomposition. Then if we multiply both sides of the equation Y = Xβ + ε by B−1, we get an equivalent linear model Y* = X*β + ε*, where Y* = B−1Y, X* = B−1X, and ε* = B−1ε. In this model Var[ε*] = B−1ΩB−1 = I. Thus we can efficiently estimate β by applying OLS to the transformed data, which requires minimizing
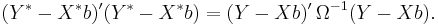
This has the effect of standardizing the scale of the errors and “de-correlating” them. Since OLS is applied to data with homoscedastic errors, the Gauss–Markov theorem applies, and therefore the GLS estimate is the best linear unbiased estimator for β.
Weighted least squares
A special case of GLS called weighted least squares occurs when all the off-diagonal entries of Ω are 0. This situation arises when the variances of the observed values are unequal (i.e. heteroscedasticity is present), but where no correlations exist among the observed values. The weight for unit i is proportional to the reciprocal of the variance of the response for unit i.
Feasible generalized least squares
Feasible generalized least squares is similar to generalized least squares except that it uses an estimated variance-covariance matrix since the true matrix is not known directly.
The ordinary least squares (OLS) estimator is calculated as usual by
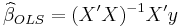
and estimates of the residuals 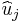 are constructed.
are constructed.
Construct 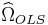 :
:
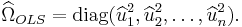
Estimate 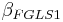 using using weighted least squares
using using weighted least squares
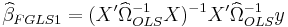
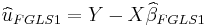
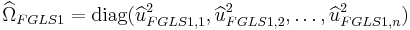
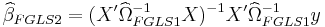
This estimation of 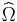 can be iterated to convergence given that the assumptions outlined in White hold.
can be iterated to convergence given that the assumptions outlined in White hold.
The WLS and FGLS estimators have the following distributions